
Neste post irei dar a conhecer um bocadinho sobre o paper de Shuyi Yu e Yuting Zhu: “Challenges Facing Algortihm Decision Marking: A Field Experiment on Repeated Marketing Campaigns“
Este artigo aborda o tema dos algoritmos, que podem ser utilizados em campanhas de marketing repetidas, sem que os utilizadores das aplicações ou redes sociais o percebam. Para se conseguir perceber como funcionam, os investigadores realizaram uma experiencia onde são utilizados diferentes algoritmos numa campanha de marketing de forma repetitiva.
Antes de aprofundar este estudo, deixo aqui um vídeo, onde explicam, de forma simples, o que é um algoritmo e como estes funcionam.
Qual a teoria utilizada para este artigo?
Basicamente, este artigo está relacionado com 5 correntes distintas de literatura:
- A literatura que se foca na segmentação de clientes com base nos seus comportamentos anteriores;
- A literatura emergente que discute a aplicação de uma máquina de aprendizagem de métodos avançados na segmentação;
- A literatura que se foca no uso de métodos de otimização dinâmica em campanhas de marketing repetidas, com a qual este estudo está intimamente relacionado;
- A literatura que está relacionada com os estudos de comportamentos estratégicos dos consumidores;
- A literatura onde se debate a relação entre big data e competição de mercado.
Tendo em conta que o terceiro ponto é relevante para o desenvolvimento deste estudo, é importante perceber um pouco mais sobre o mesmo, e o que autores referem sobre os métodos de otimização dinâmica.
Desta forma, são citados no artigo 4 autores sobre este tema, sendo eles: Gonul e Shi (1998), Simester et al. (2006), Zhang et al. (2014) e Hauser et al. (2009).
Os autores Gonul e Shi (1998) propõem um modelo de programação dinâmica estrutural, com o intuito de desenhar uma política ótima de direct mail num ambiente dinâmico, onde os consumidores consigam entender a estratégia utilizada no e-mail enviado pela empresa, para desta forma maximizarem a sua utilidade a longo prazo.
O autor Simester et al. (2006) resolve as políticas de correspondência por catálogo sequencial, ao utilizar uma abordagem de otimização dinâmica, que poderá vir a ser promissora. No entanto, esta abordagem apresenta um desempenho inferior no que toca a clientes de alto valor para a empresa.
Zhang et al. (2014), ao utilizarem um modelo hierárquico Baysiano escondido no modelo de Markov, num ambiente Business to Business (B2B), encontraram a política ótima de preços direcionados dinâmicos, já Hauser et al. (2009) aplicam um modelo, parcialmente observável de Markov, de processo de decisão ao problema de morphing de websites.

Por onde começaram…
A pergunta de partida para a elaboração deste paper é: “Como os consumidores respondem às campanhas de marketing repetidas conduzidas por algoritmos?”
Os autores tencionam, também, perceber como é que as respostas variam entre diferentes algoritmos utilizados neste tipo de campanhas de marketing.
Como o fizeram…
O método de investigação utilizado neste artigo foi o método experimental, que consiste em submeter os objetos de estudo à influência de certas variáveis, em condições controladas e conhecidas pelos investigadores, com o intuito de observar os resultados que a variável produz no objeto.
Para esta experiência em específico, os autores colaboraram com uma startup de entrega de comida em 11 cidades dos Estados Unidos. A única característica deste serviço é que eles não oferecem apenas o serviço de entrega tradicional, em que os pratos são pedidos à la carte, permitem também que os utilizadores peçam marmitas nos dias de semana por uma pequena taxa de entrega foxa – 1$.
Neste estudo, eles consideraram apenas este serviço de marmitas e os clientes que a pediram; e assim, ao focarem-se apenas neste serviço, a plataforma ofereceu o cenário perfeito para a experiência, isto porque estes pedidos são regulares e fáceis de modelar, tendo em conta que as pessoas almoção apenas uma vez a cada dia da semana, e por isso, o número de pedidos numa determinada semana pode apresentar a maioria das informações sobre a tendência de compra de um cliente e a sua disposição para realizar o pagamento.
Shuyi Yu e Yuting Zhu deram início à experiência dia 14 de abril de 2019, e recrutaram sujeitos que eram utilizadores ativos do serviço de almoço, que fizeram pelo menos um pedido no mês anterior, na área de Chicago. Esta experiência durou 6 semanas (até ao dia 24 de maio de 2019).
Neste estudo existe um grupo de controle e dois grupos de tratamento – um para a regra de segmentação baseada no modelo OLS simples, e outro para a regra de segmentação conduzida pelo modelo LASSO). Cada grupo tem cerca de 200 utilizadores, e foram utilizadas amostragens de clusters, havendo 72 clusters e cada um deles consiste nos utilizadores fazerem as suas encomendas no mesmo local. Estes clusters são depois escolhidos ao acaso para os grupos de tratamento. Nestes grupos de tratamento é entregue um cupão aos utilizadores para poderem utilizar.
Para melhor perceber esta metodologia segue uma imagem onde conseguimos ver o processo de atribuição de tratamento nos respetivos clusters:
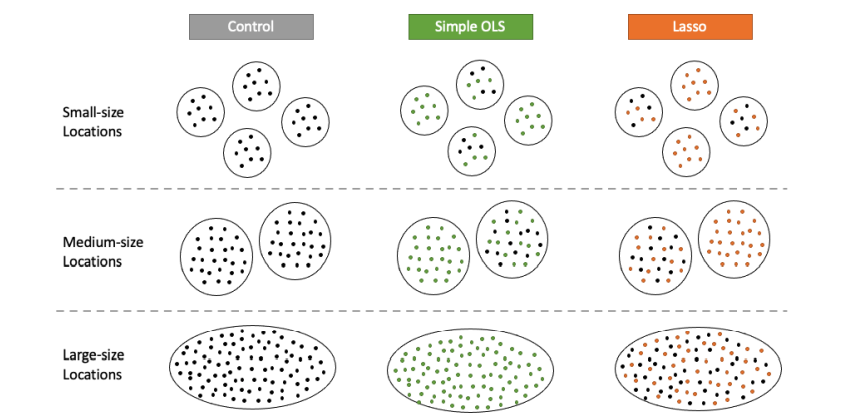
Passando a explicar a imagem… os utilizadores são agrupados nos clusters tendo em conta a localização do levantamento das encomendas, que por sua vez estão divididas em 3 grupos (small, medium e large) consoante o número de utilizadores que têm. De seguida é aplicada uma amostragem aleatória simples em cada estrato, e um terço dos locais são selecionados em cada grupo de tratamento. Para essas localizações selecionadas na Simple OLS e LASSO, existe 50% de probabilidade de os utilizadores da localização serem tratados pelo respetivo tratamento; por outro lado, apenas metade de todos os utilizadores vão ser tratados.
No que diz respeito às regras de segmentação, no estudo, os investigadores optaram por dois modelos, como já referi anteriormente:
- Modelo OLS simples – com apenas uma variável explicativa que o número de compras feitas na semana anterior
- Modelo LASSO (Least Absolute Shrinkage and Selection Operator) – onde mais variáveis são consideradas, como por exemplo: o número de encomendas na semana anterior, o mínimo / a média / a despesa máxima na semana anterior, número de pratos únicos / as categorias / os restaurantes por encomenda na semana anterior, etc.
O que concluíram…
Nesta experiência os investigadores registaram o comportamento de compra de 594 utilizadores ao longo das 6 semanas, incluindo quando e o que compraram, assim como as informações de uso dos cupões entregues (1 689 durante toda a experiência).
Aproximadamente 11% dos cupões foram recomendados por utilizadores, o que é superior à taxa média de aceitação no que diz respeito a campanhas de cupões por e-mail.
Concluíram também que a taxa de “resgate” do cupão varia ao longo das semanas:
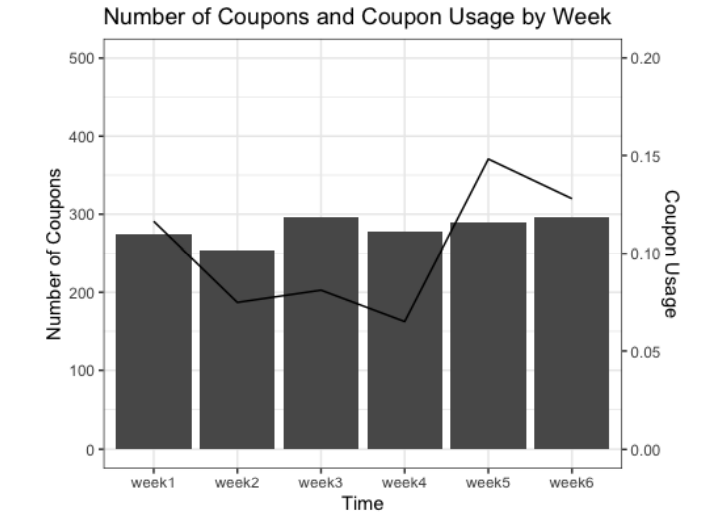
Os investigadores referem que é plausível que as pessoas estejam mais propensas a resgatar os cupões depois de já terem recebido vários, o que sugere que a repetição das ações pode aumentar a eficácia das campanhas de marketing.
Ao realizar esta experiência, Shuyi Yu e Yuting Zhu, mostraram que, a longo prazo, algoritmos mais avançados que utilizem mais informações têm um melhor desempenho do que algoritmos mais simples, mesmo que a curto prazo não produzam melhores resultados de previsão e não superem os algoritmos mais simples. Segundo os autores, esta diferença deve-se ao facto de que os algoritmos avançados impedem que os cliente aprendam os mesmos com tanta facilidade e joguem estrategicamente contras os mesmos.
Implicações
Como todos os papers realizados, existem sempre implicações teóricas e gerais que podemos retirar dos mesmos.
Assim, este estudo é importante a nível teórico tendo em conta que foi um primeiro passo para entender se os consumidores têm consciência do algoritmo e como estes respondem às ações de marketing baseadas em algoritmos a longo prazo. Os resultados obtidos através desta experiência contribuíram para a literatura que estuda os comportamentos estratégicos dos consumidores, assim como para recente debate da relação entre big data e competição de mercado.
Já numa perspetiva geral, os resultados obtidos são importantes para os profissionais de marketing, uma vez que sugerem que os consumidores podem ter algum nível de conhecimento sobre algoritmos, pelo menos quando estes são simples, e são prospetivos o suficiente para jogar estrategicamente contra as estratégias de marketing alimentadas por algoritmos. Assim, os marketeers que estão cientes disto, podem beneficiar ao ter em consideração as respostas estratégicas.
Escrito por: Mariana Silva